The Data Lifecycle Lowdown: Data Processing & Data Processing Engines
May 03, 2022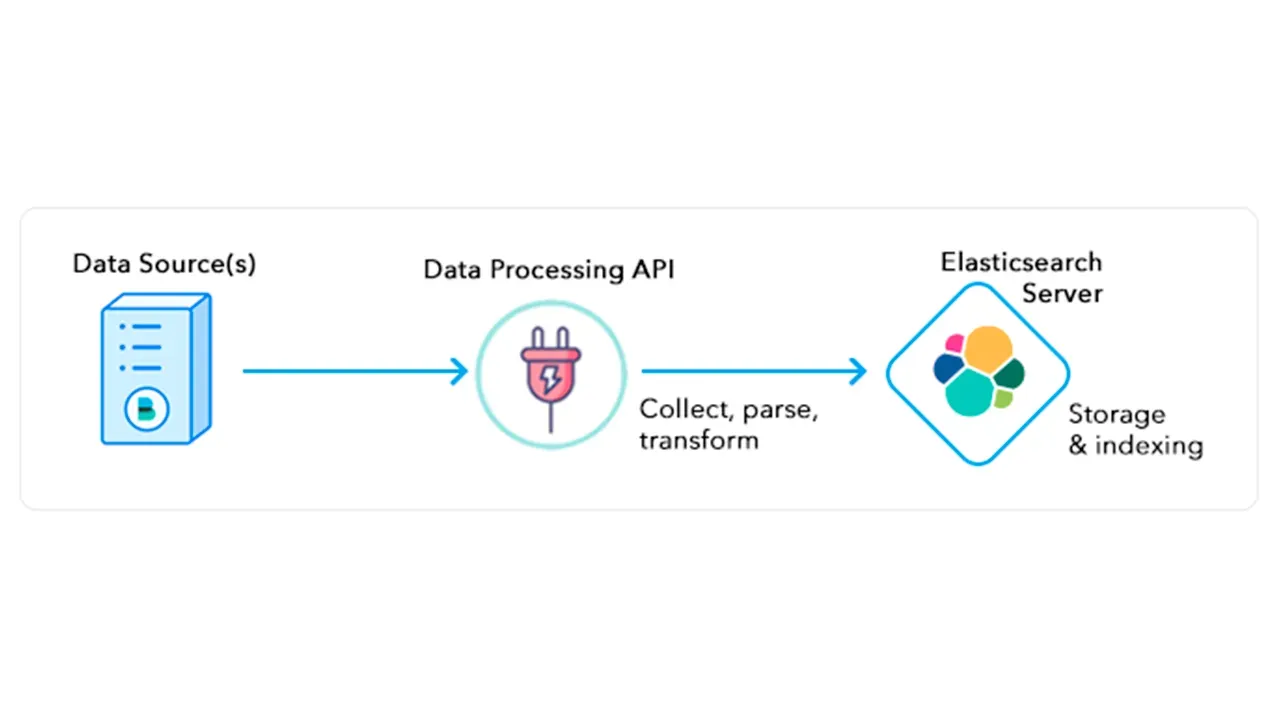
Want to become more technical in just 5 weeks? Find out how the Skiplevel program can help.
Here's a question: how familiar are you with the data lifecycle?
If the answer is not familiar at all, or a little, you don't want to miss this article. I'm going to give you an intro to the data lifecycle along with its stages and I'll dig a bit deeper into stage 3: data processing.
You'll also learn about LogStash–the L of the ELK stack we've been covering in previous articles (see the Elasticsearch articles here).
Intro to the Data Lifecycle
We collect data for many reasons, but one of the most important reasons is to extract important business insights from it–a key part of data analytics and data science.
This process of extracting important insights from raw datasets is called the data lifecycle, and the structure set up to monitor this process is known as the data management lifecycle.
The lifecycle of data takes us from planning what data to collect all the way to storing data. Depending on your company and which data expert you ask, there can be anywhere from 5-8 lifecycle stages, but here are 6 broad stages:
👉 Stage 1 Planning: Decide what data to collect ↓
👉 Stage 2 Acquire: Collect the raw data ↓
👉 Stage 3 Process: Clean and manipulate the data to get ready for analysis ↓
👉 Stage 4 Storing: Organize and copy data into DB(s) for access and retrieval ↓
👉 Stage 5 Analyze: Extract useful insights from processed data ↓
👉 Stage 6 Visualizing: Create graphical representations of information
There's lots to learn about each stage in the data lifecycle but in this article we're going to dig a bit more into stage 3: data processing.
What is data processing and why is it important?
Data processing is critical for any organization looking to create better business strategies and increase their competitive edge.
When we first collect data, it's known as raw data, or data that's directly collected from the source and has not been cleaned, processed, or transformed. In order for us to extract utility from a raw dataset, all data in the dataset has to:
- 👉 Be uniform: Data follow a predictable pattern/structure (i.e. MM/DD/YYYY for dates)
- 👉 Have Integrity: Inaccurate or fake data is removed to preserve data integrity (i.e. fake addresses or fake names)
- 👉 Be Searchable: How do we organize and quickly search through large data sets? (i.e. Organize datasets based on last name, location, etc..)
This is where data processing comes in. In data processing, raw data is collected, filtered, and sorted in order to achieve the above characteristics before moving on to the next stage for analysis.
Data processing engines to the rescue: Introducing LogStash
Data processing can be quite complex depending on the size of the dataset and the type/format of the raw data.
Let's take log data as an example of data complexity. In the last article on logging I included some examples of what log data looks like. Here's a refresher on access logs:
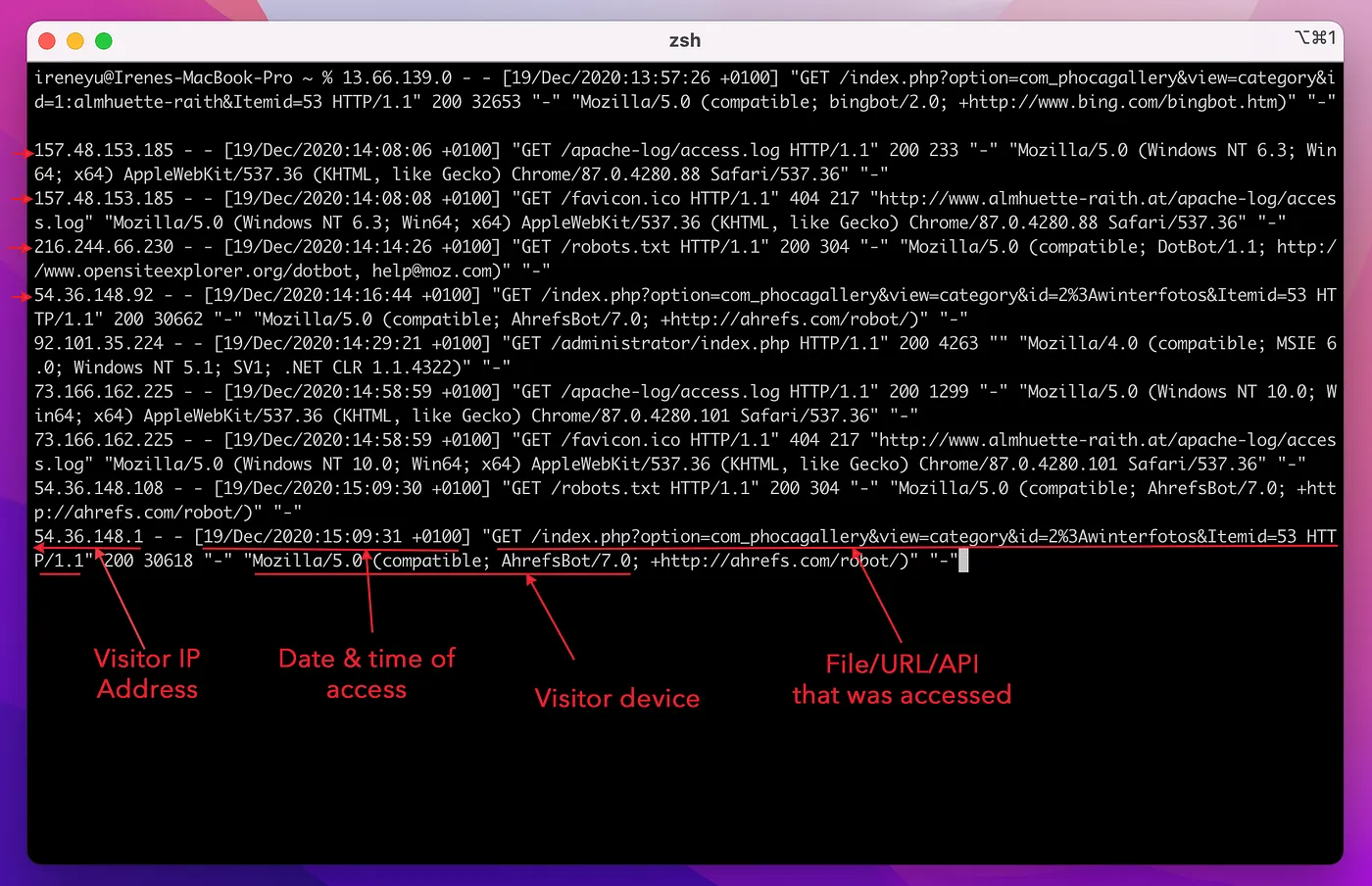
Notice how unstructured the raw access log data is. In order to extract any value from it, we need to process it to extract out the info we want into their own separate fields (i.e. visitor IP address, visitor device, etc..) while also cleaning and formatting the data.
To do this, teams and companies need a pipeline tool called data processing engines or data collection engines to pipe in raw data, run some rules/ algorithms on it, and spit out the final processed data before storing it somewhere.
Introducing LogStash
LogStash is a powerful open source data collection engine with real-time pipelining capabilities. LogStash has capabilities that extend well beyond just processing log data. However, it is known for originally driving innovation in log collection, hence the name LogStash. Regardless, LogStash is a popular data processing engine used by data and software teams everywhere to process all types of data.
How does LogStash work?
All data processing engines use a pipeline structure with multiple stages to process data.
The LogStash events processing pipeline has 3 stages: input → filter → output. Inputs generate events, filters modify them, and outputs ship them elsewhere. LogStash defines these stages in a configuration file called logstash.conf.
Below is a very simple code example of a Logstash configuration file. This file is defined by an engineering team and uploaded their LogStash account.
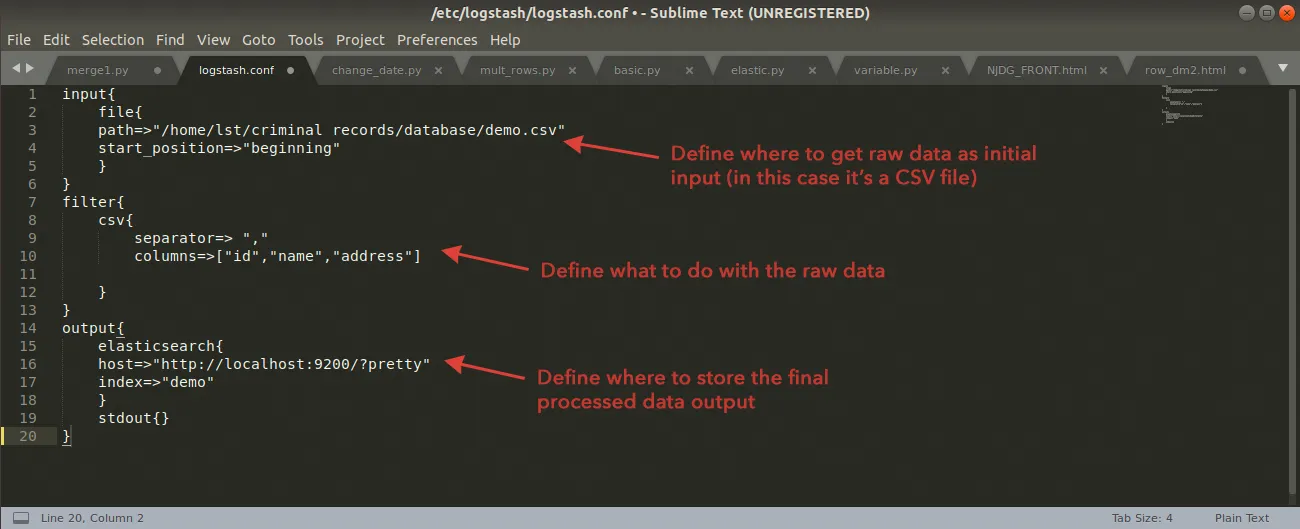
Notice how the file is sectioned out into the 3 stages of input, filter, and output. Logstash supports various operations within each stage that you can read more about here if you're curious.
Take a step back for the big picture
If you're subscribed to Skiplevel's newsletter and have been paying attention, you'll realized just how much we've covered, and we've covered a lot. In the last post we covered software logs. In this article we talked about data processing, data processing engines, and LogStash in particular as part of the popular ELK stack. Skiplevel's December newsletter issue also covered Elasticsearch as part of the ELK stack.
Remember as a non-engineering tech person working with engineers, the depth of detail is not as important as a breadth of knowledge. So if there's one visualization in your mind you should be walking away with from all 3 newsletter issues, it's this flow diagram below:
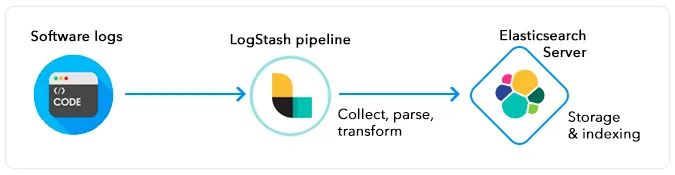
Sign up for the Skiplevel newsletter to get more content like this straight to your inbox.
Learn more about the Skiplevel program ⟶
Connect with Irene on LinkedIn and Twitter and follow Skiplevel on LinkedIn, Twitter, and Instagram.
Become more technical without learning to code with the Skiplevel program.
The Skiplevel program is specially designed for the non-engineering professional to give you the strong technical foundation you need to feel more confident in your technical abilities in your day-to-day role and during interviews.

Fullstack software engineer and tech mentor to product managers. Follow Irene on Medium!